
Any fool can write code that a computer can understand. Good programmers write code that humans can understand. — Martin Fowler
Coder to the People
Design is about your audience. It's why the renowned designer Dieter Rams said, "Indifference towards people and the reality in which they live is actually the one and only cardinal sin in design."
Naming Things: The Hardest Problem in Software Engineering is a short book I recommend. It outlines principles for naming things in your code, like functions, variables, or column headers, so your coworkers won't hate you. This audience also includes your future self: when you return to old code and have to relearn what it did.
If you code little and mostly work in Excel, these ideas extend to the labels that top your columns. It also applies to Excel named ranges if you, unfortunately, choose to forgo the great flexibility of not having to name ranges in Excel!
For the columns example, I've worked on projects where concise but vague column labels are used, like "Units," "Factor," or "Total." While all technically correct, the level of abstraction is off. Specificity is the remedy. For example, are the units "Pharmacy Scripts," "Reams of Paper," or "Weight in Pounds"? Names like "Factor" are vague and prone to inconsistency. The model might call the same concept a "Factor" in one spot, a "Rate" in another, and finally, an "Adjustment" somewhere else.
Linking Verbs
One of my favorite ideas from Naming Things is the advice to use linking verbs in naming Boolean objects (where the values are binary, like TRUE or FALSE, or 1 or 0).
While I'll be focused on linking verbs, consistency will be the largest benefit to naming things. Have your team agree to the rules. Then, externalize, teach, and enforce them. I'll still argue my justifications for certain styles next. However, team consistency is the priority when naming things. Then you can explore for improvements.
For example, in many projects, the team discusses "flagging" certain features in the data. It's as if your front lawn has become a grid, and you walk around placing little sprinkler flags in the grass where a variable meets your criteria. The analogy leaks into the naming, and suddenly, you have variables, fields, or columns with a "_flag" postfix: drug_flag, county_flag, income_threshold_flag, and so on.
Instead, skip the analogy (left) and use the linking verb directly (right):
drug_flag → is_drug_claim
county_flag → is_maricopa_county_az
income_threshold_flag → has_met_income_threshold
Consistency by the Numbers
Another issue with the "flag" name is that it is unclear what values it can take. For example, one flag has the values Y or N only for the next flag to be Include, Exclude, and then another flag is multi-value! Yes, No, Unknown, Maybe, I Give Up. Or you have related variables with values representing the same concepts, but instead of consistency, you get fancy variations: enrollee, beneficiary, participant, member, policy holder, recipient, so forth.
Updating to a linking verb better forces the binary than a flag name. You see "is_x" and think it is "x" or not—TRUE or FALSE, 1 or 0.
Another advantage of the 0/1 values in a linking verb-named variable is you can use the 0/1 values directly. For example, suppose I have two variables: People who have read Statistical Rethinking and people who use the Bayesian software Stan.
has_read_statistical_rethinking
is_stan_userUsing common math functions, I can look at counts, proportions, or filters. This code simulates some binary data:
set.seed(20250125)
sim_n <- 1e3
has_read_statistical_rethinking = rbinom(sim_n, 1, 0.20)
# More likely a user if they read rethinking
stan_user_prob <- 0.10 + 0.35 * has_read_statistical_rethinking
is_stan_user <- rbinom(sim_n, 1, stan_user_prob)
head(
cbind(
has_read_statistical_rethinking,
stan_user_prob,
is_stan_user
)
)
has_read_statistical_rethinking stan_user_prob is_stan_user
[1,] 0 0.10 0
[2,] 1 0.45 0
[3,] 1 0.45 1
[4,] 0 0.10 1
[5,] 0 0.10 0
[6,] 0 0.10 1
Now we can look at some counts and proportions :
> add margins(table(has_read_statistical_rethinking, is_stan_user))
is_stan_user
has_read_statistical_rethinking 0 1 Sum
0 765 46 811
1 85 104 189
Sum 850 150 1000
> add margins(table(has_read_statistical_rethinking, is_stan_user)) / sim_n
is_stan_user
has_read_statistical_rethinking 0 1 Sum
0 0.765 0.046 0.811
1 0.085 0.104 0.189
Sum 0.850 0.150 1.000
Now, wait a minute! You could have had string values and make this work the same, like this:
> add margins(table(has_read_statistical_rethinking, is_stan_user)) / sim_n
is_stan_user
has_read_statistical_rethinking Not a user User Sum
No 0.765 0.046 0.811
Yes 0.085 0.104 0.189
Sum 0.850 0.150 1.000Yes. But that simulation would then need factor data types, and you introduce uncertainty about whether the variable is binary and what values it takes. If you really need the labels, like in this prior output, do it ad-hoc or save it for a final presenting step where it's reasonable to switch from an internal coding audience to a non-coding audience.
Back to the 0/1, here is an example of how clean it is to get subsequent statistics with standard formulas:
# How many have read Rethinking
> sum(has_read_statistical_rethinking)
[1] 189
# Proportion who have read Rethinking
> mean(has_read_statistical_rethinking)
[1] 0.189
# Proportion who have read Rethinking and are Stan users
> mean(has_read_statistical_rethinking * is_stan_user)
[1] 0.104
# Proportion who have not read Rethinking and are Stan users
> mean((1 - has_read_statistical_rethinking) * is_stan_user)
[1] 0.046
# Proportion of users given they have read Rethinking
> sum(has_read_statistical_rethinking * is_stan_user) / sum(has_read_statistical_rethinking)
[1] 0.5502646
Moreover, this summarizing works in Excel without needing =COUNTIFS() or =IF() to convert string values or worry about hardcoded strings in your formulas. Compare how long this formula is in the top table versus the straightforward bottom table:
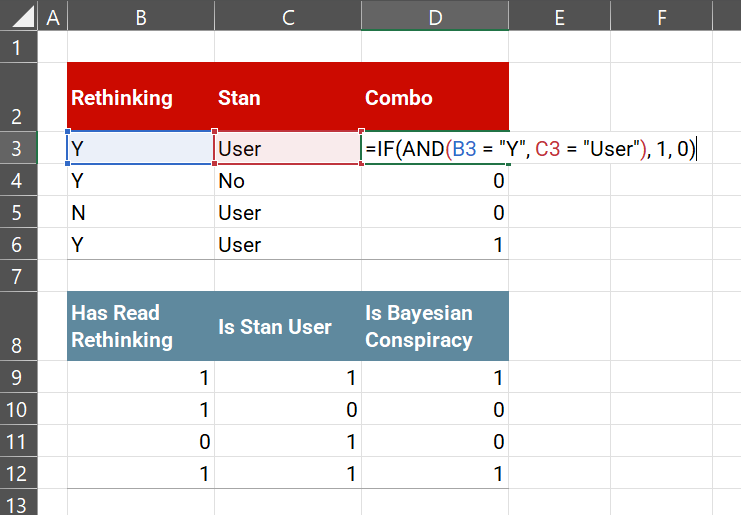
You can probably guess the formulas starting at the top of cell D9, which is good because Excel hides things. Cell D9 is column B multiplied by column C, which is easier to write and read than the shown formula.
Fun little secret, you can get to 0/1 directly with TRUE or FALSE in both R and Excel—with a trick. In Excel, the -- converts Boolean TRUE or FALSE to integers 1 or 0, respectively.
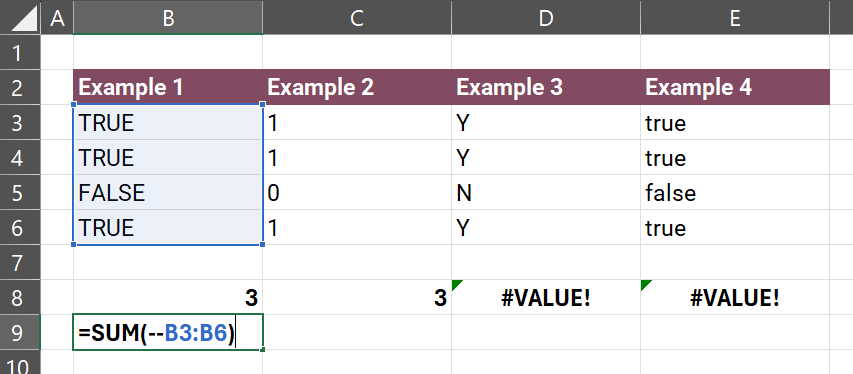
Note how we get 3 for Examples 1 and 2, but strings in 3 and 4 don't work. Next is the same idea, but in R. No tricks.
# Example 1
> sum(c(1, 1, 0, 1))
[1] 3
# Example 2
> sum(c(TRUE, TRUE, FALSE, TRUE))
[1] 3
# Example 3
> sum(c("Y", "Y", "N", "Y"))
Error in sum(c("Y", "Y", "N", "Y")) :
invalid 'type' (character) of argument
# Example 4
> sum(c("true", "false", "true", "true"))
Error in sum(c("true", "false", "true", "true")) :
invalid 'type' (character) of argumentHowever, because it may not be intuitive that math operators work on TRUE/FALSE, I still promote the 0/1 approach.
Positive Vibes Only
Last, positive framing plays into the 0/1. A positive frame avoids negation, which isn't easy. (See what I did there?). For example, I could say that, "I didn't like the game Everdell." But rework the sentence, and you get, "I dislike the game Everdell" (but I love Brass: Birmingham). This same concept is useful for succinct and understandable prose. The cognitive load on your audience is eased by dropping double negatives:
- Negative:
not_inactive_account - Positive:
is_active_account
Now, "active" is the positive, which takes the 1 value, or you can rework your variable names so the active works for your desired context:
- Positive:
is_active_account - Positive:
is_inactive_account
Absolution
I've only covered some concepts from Naming Things. If this resonates with you, check out the book and learn more. Sidestep the only cardinal design sin by thinking about who has to read your code and workbooks—including your future self. You can start as soon as your next variable.
Benner, T. (2023). Naming Things: The Hardest Problem in Software Engineering. Independently published. https://www.namingthings.co/
Lovell, S. (2011). Dieter Rams: As Little Design as Possible. Phaidon Press.
This website reflects the author's personal exploration of ideas and methods. The views expressed are solely their own and may not represent the policies or practices of any affiliated organizations, employers, or clients. Different perspectives, goals, or constraints within teams or organizations can lead to varying appropriate methods. The information provided is for general informational purposes only and should not be construed as legal, actuarial, or professional advice.

{kind=link}